
Abstract
Collecting large-scale egocentric video datasets with dense spatial and temporal annotations is costly, slow, and often constrained by environmental biases, privacy constraints, and limited coverage of interaction patterns. While synthetic data has shown strong potential in several vision domains, its use for egocentric perception remains relatively underexplored, especially for tasks requiring temporally coherent human-object interactions. In this work, we introduce EgoInteract, a controllable simulator for egocentric video generation designed to model fine-grained egocentric interactions and their temporal dynamics. The simulator enables precise control over camera, human body and hand motion, object manipulation, and scene composition across diverse environments. Building on this framework, we generate a synthetic egocentric video dataset with dense spatial and temporal annotations for temporal action segmentation, next-active object detection, interaction anticipation, and hand-object interaction detection. We evaluate models trained with simulated data on multiple real-world egocentric benchmarks spanning diverse environments, object categories, and interaction patterns. Results show consistent improvements over strong baselines across tasks and datasets, demonstrating the effectiveness and transferability of our simulation-based approach.
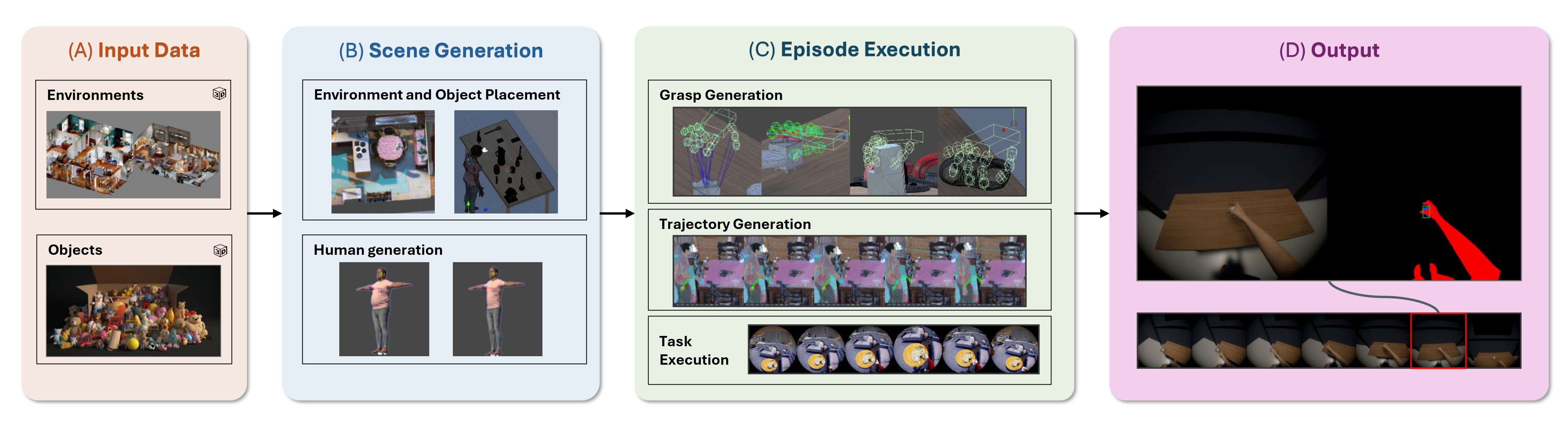
EgoInteract is a controllable simulation framework for generating synthetic egocentric video data with fine-grained spatial and temporal annotations. It supports precise modeling of camera motion, hand-object interactions, and scene dynamics, enabling large-scale dataset generation for tasks such as temporal action segmentation, next-active object detection, and interaction anticipation. Models trained on EgoInteract demonstrate consistent improvements and strong transferability across multiple real-world egocentric benchmarks.

Examples of interaction episodes generated by EgoInteract. Each row shows a different procedurally generated episode in a distinct indoor environment, showing the diversity of egocentric views, object configurations, and scene layouts produced by the simulator.
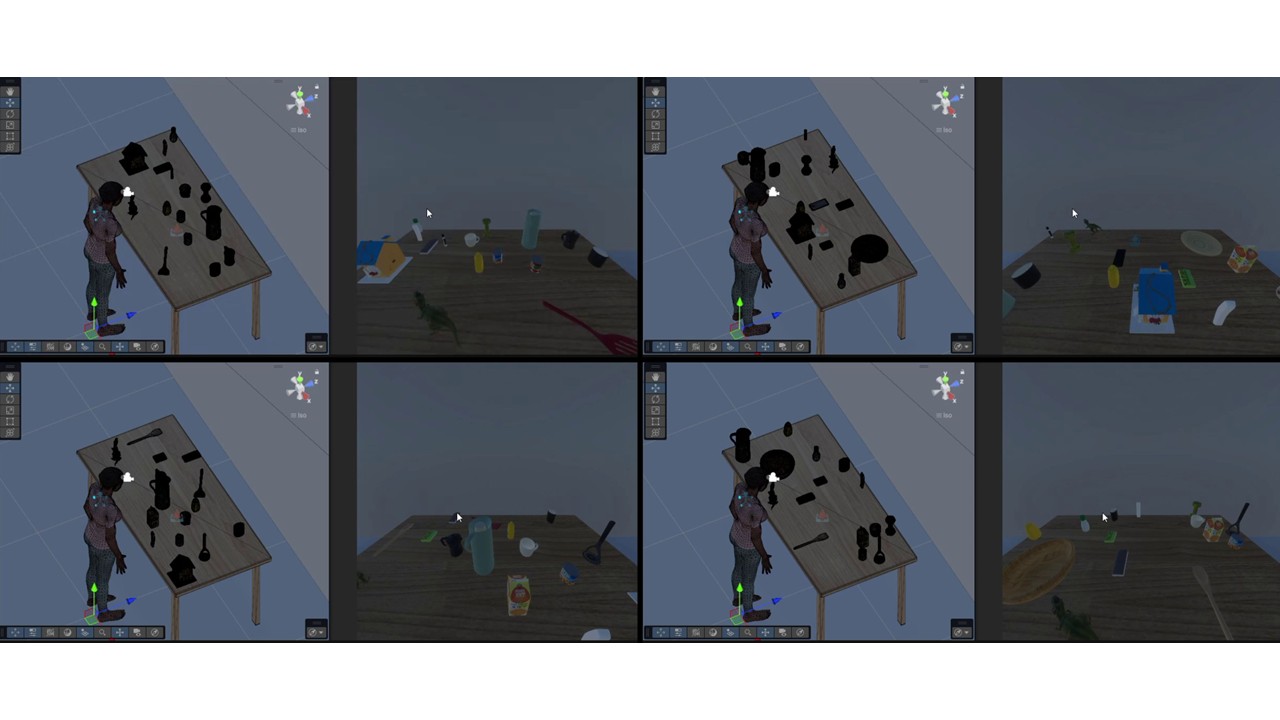
Examples of procedurally generated tabletop scenes in EgoInteract. For each example, the left image shows the global scene configuration, while the right image shows the corresponding egocentric view observed by the embodied agent.

Examples of avatar appearance randomization in EgoInteract. The figure shows variations in clothing texture and visual appearance across episodes.
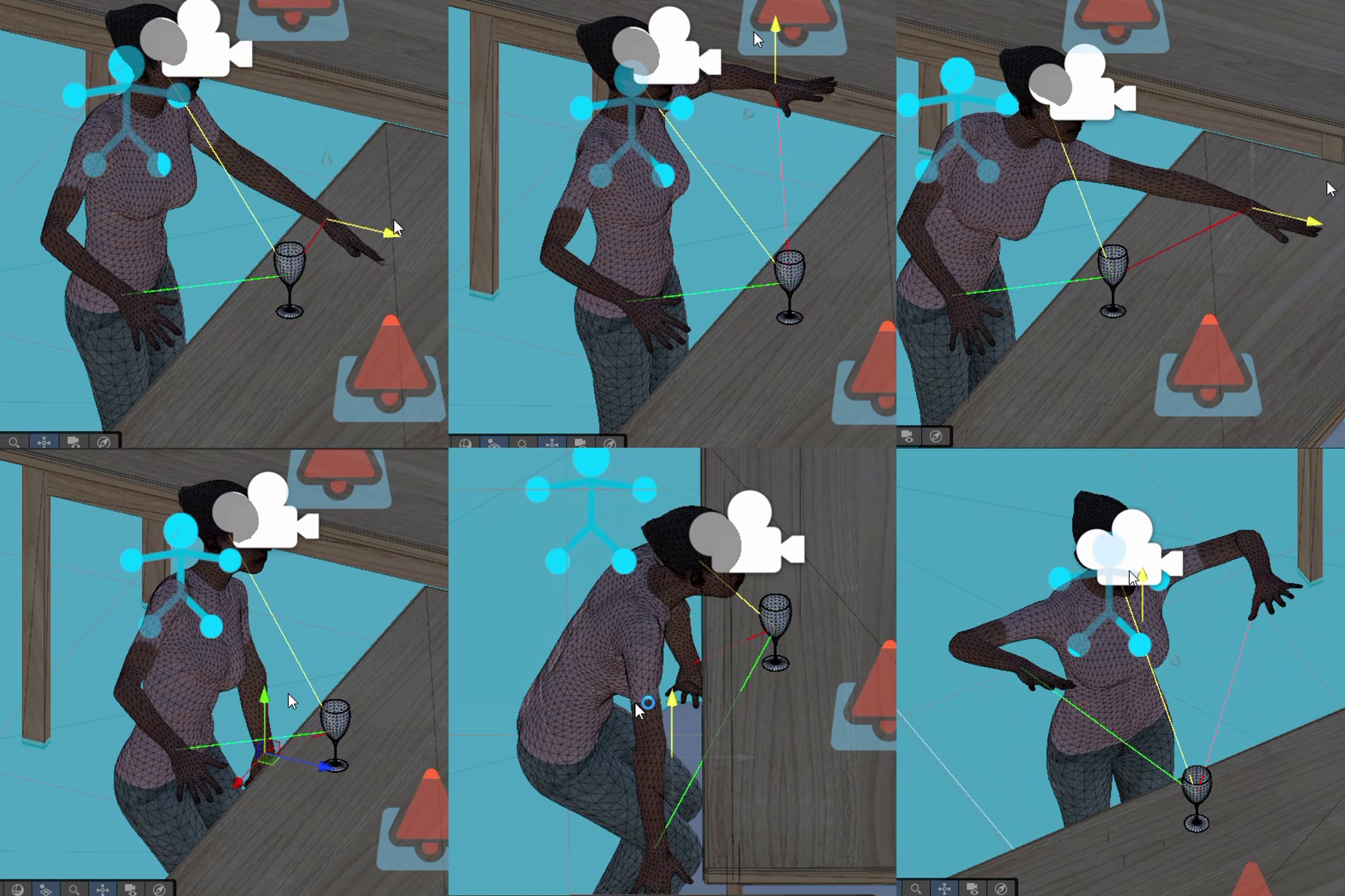
Examples of full-body inverse kinematics in EgoInteract. Given target hand poses, the IK solver generates coordinated whole-body configurations involving the arm, torso, and head to produce plausible egocentric interaction poses.
Videos
BibTeX
@article{leonardi2026egointeract,
title={EgoInteract: Synthetic Egocentric Videos Generation for Interaction Understanding and Anticipation},
author={Leonardi, Rosario and Ragusa, Francesco and Materia, Daniele and Passanisi, Alessandro and Fort, James and Engel, Jakob and Farinella, Giovanni Maria},
journal={arXiv preprint arXiv:2605.18214},
year={2026}
}Acknowledgments
Research at University of Catania has been supported by Meta, Next Vision, and by the project Future Artificial Intelligence Research (FAIR) – PNRR MUR Cod. PE0000013 - CUP: E63C22001940006.

